
データ上、1〜8番人気が狙い目、とはいえ、平均を取るように、平らにならすとそうなるわけで、レースごとに片寄りはあるわけです。
荒れるレースは、予想がしづらく、みんなが迷うので、幅広い範囲でオッズが拮抗する、硬いレースはオッズの階層がきれいに分かれて人気寄りになる、というわけです。
試しに、2023年1月の重賞レースのオッズをまとめてみました。
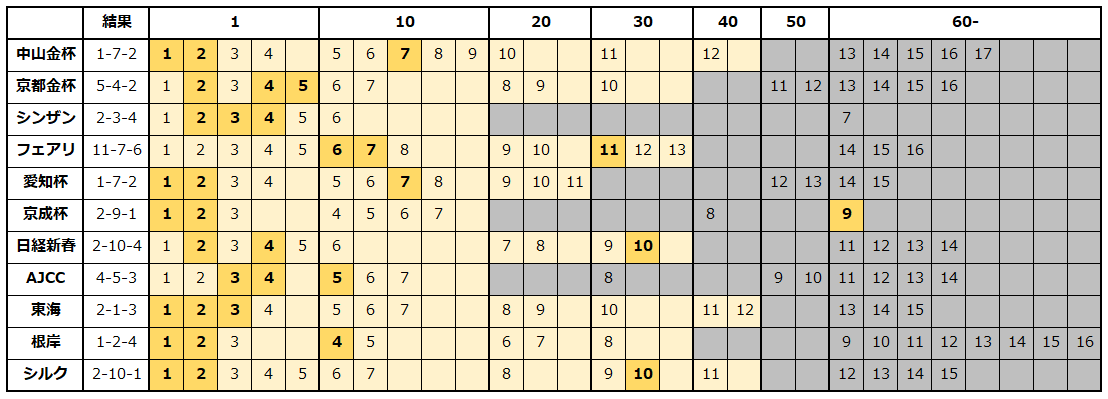
人気のある馬は多く馬券にからみ、特に1〜2番人気の発生も多いことが、この表でも分かります。
また、5〜7番人気は穴っぽく感じますが、単勝10倍台であり、それなりに人気を集めているわけなので、一桁台とそこまで差がないということも言えます。
一方で、20倍以上になると極端に少なくなり、穴が来たとしても1頭だけです。
黄色く塗った部分と、グレーに塗った部分があります。黄色とグレーの階層の境界線は、10倍ごとに区切ったときに空白があって、飛んでいるところです(10倍台の次に30倍倍台に飛ぶなど)。
世の中のオッズ理論では、10倍ごとに区切るのではなく、増加率を見ることが多いようです(60倍と40倍は1.5倍差、のように)が、計算がとても大変なので、シンプルに10倍台区切りでまとめました。
これを見ると、京成杯の1レースを除いて、階層の黄色側で決まっています。これはある程度、法則として使えるかもしれません。
そこでさっそく、上記の法則が当てはまるか、去年のレース結果で何件か検証してみたところ、微妙に、黄色の範囲を越える穴馬が来たりして、なかなかうまくいきませんでした。
まだ20レースくらいしかシミュレーションしていないので、数多く調べれば、当てはまるレースも増えるかもしれませんが、今のところは微妙な印象です。
そう考えると、結局は、もっとサンプル数を増やし、極端な高配当の結果は除外して、発生数の高いところを集計して分析しないと、安定した法則として使うのは難しいと言えそうです。
実際の話、1月は結構堅い結果が多かったように感じます。この結果がずっと続くとは思えませんし、もし続いたら、いろいろと困ります。
あらためて考えた結果、以下のようにしてみようかなと考えています。
■上位3頭(1〜3番人気)
・2頭を選び、◎▲とする
■中位(4番人気〜10倍台)
・2頭を選び、◎◎とする
■穴馬(20倍台以上)
・1頭を選び、▲とする
■買い方
・◎◎◎▲▲三連複フォーメーション7点
・◎ワイド3点
■シミュレーション
・1-2-3番人気 → ハズレ
・1-2-x 1-3-x 2-3-x
→ x◎◎
・1-x-y 2-x-y 3-x-y
・上位1頭が◎ → xy◎◎▲
・上位1頭が▲ → xy◎◎
・x-y-z
・xが◎ → yz◎◎▲
・xが▲ → yz◎◎◎